
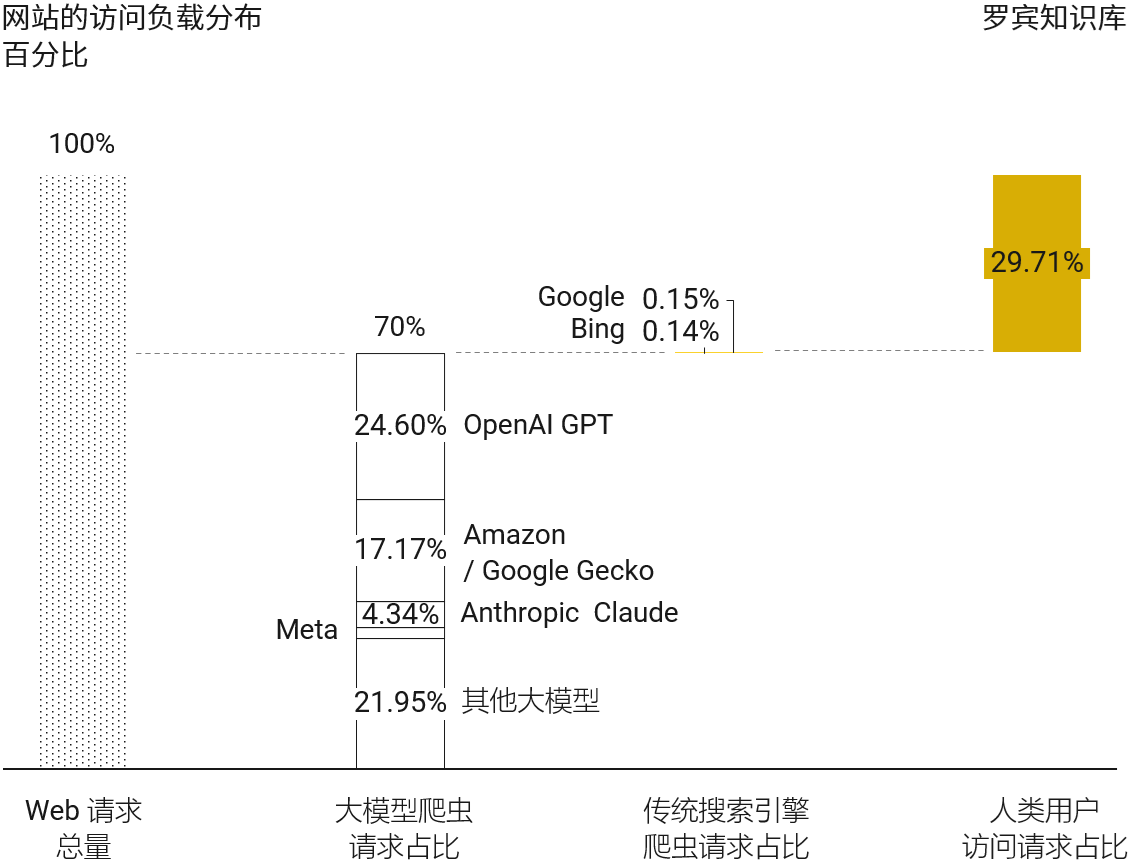
Mozilla 工程师 Dennis Schubert 通过其参与维护的 diaspora 开源项目的网站访问日志,在过去 60 天的 Web 访问请求中,有 70% 来自大模型公司的爬虫访问。
大模型公司的这种玩法,会在事实上对内容源头的网站产生类似 DDoS 攻击的效果,即大量网站开销来在 bot 机器人。
与之形成对比的,传统搜索引擎 Google 和 Bing 的爬虫只占了网站访问负载的 0.3% 不到。
传统搜索引擎和大模型理论上都可以给内容源网站引流,但大模型爬虫比例如此之大,越来越多网站会思考 “性价比问题”。
所有网站访问中,来自人类的访问小于 30%。这也会引发一个新的思考,现行互联网的商业模式很大比例是基于用户注意力售卖的广告模式,本质是眼球经济。
如果大部分访问都不是人类访问,那广告还能否卖出去呢?
附件 PPT 来自红杉资本(Sequoia Capital)美国。
图 1:生成式 AI 目前达到了 30 亿美元的收入,大约花费了一年多时间。而 SaaS 达到类似水平花费了十年。
图 2:CB Insights 统计的已披露大模型相关投资并购案例的数据,大约 200 多亿美元的资金中,有 169 亿美元投向了基础设施,尤其是英伟达的 GPU。
根据红杉资本的研究,其认为过一年一共有 500 亿美元花费在了生成式 AI 上面(包含数据中心配套的机房、供电等)。
500 亿美元 vs. 30 亿美元,是过热了,还是伟大征程的开始?
Similarweb 监测数据显示,全球主要搜索引擎中,除了 Bing 保持增长外,其他皆没有增长或者大幅下滑。百度的访问量下滑尤其明显。
搜索引擎流量的起伏,比较多观点认为是生成式 AI 的分流影响。
但我们认为,不应忽视 “Web vs. APP” 的影响,大量搜索便在热门社交 APP(抖音、微信)或者电商(Amazon、PDD)内的搜索了。
传统 Web 生态面临越来越的的问题是,独立站的持续减少,公开 Web 的可搜索内容相对变少。
“类比” 是人类社会与生俱来的本能。
每当遇到新情境时,人类会寻求迅速剥离无关紧要的部分,透过事件表象看本质。这是一种人类无法抑制的心理条件反射。
以 < 图 1 > 代表性产品从上市到发展一亿用户需要多少时间为例,受众会条件反射般认为,ChatGPT 的潜力会比 WeChat、Tiktok、Facebook 大得多。
但实际上,ChatGPT 用户停滞增长许久了(OpenAI 最近又进一步免去用户注册要求,看能否再激活一下增长)。
< 图 2 > 代表性企业在前三年的收入,受众很容易得出结论:OpenAI 的收入变现要比 Google、Amazon、Facebook 好很多。
但实际上,整个生成式 AI 在今年会面临严峻的 “进一步的收入从哪里来的” 问题。而 Google、Amazon、Facebook...

